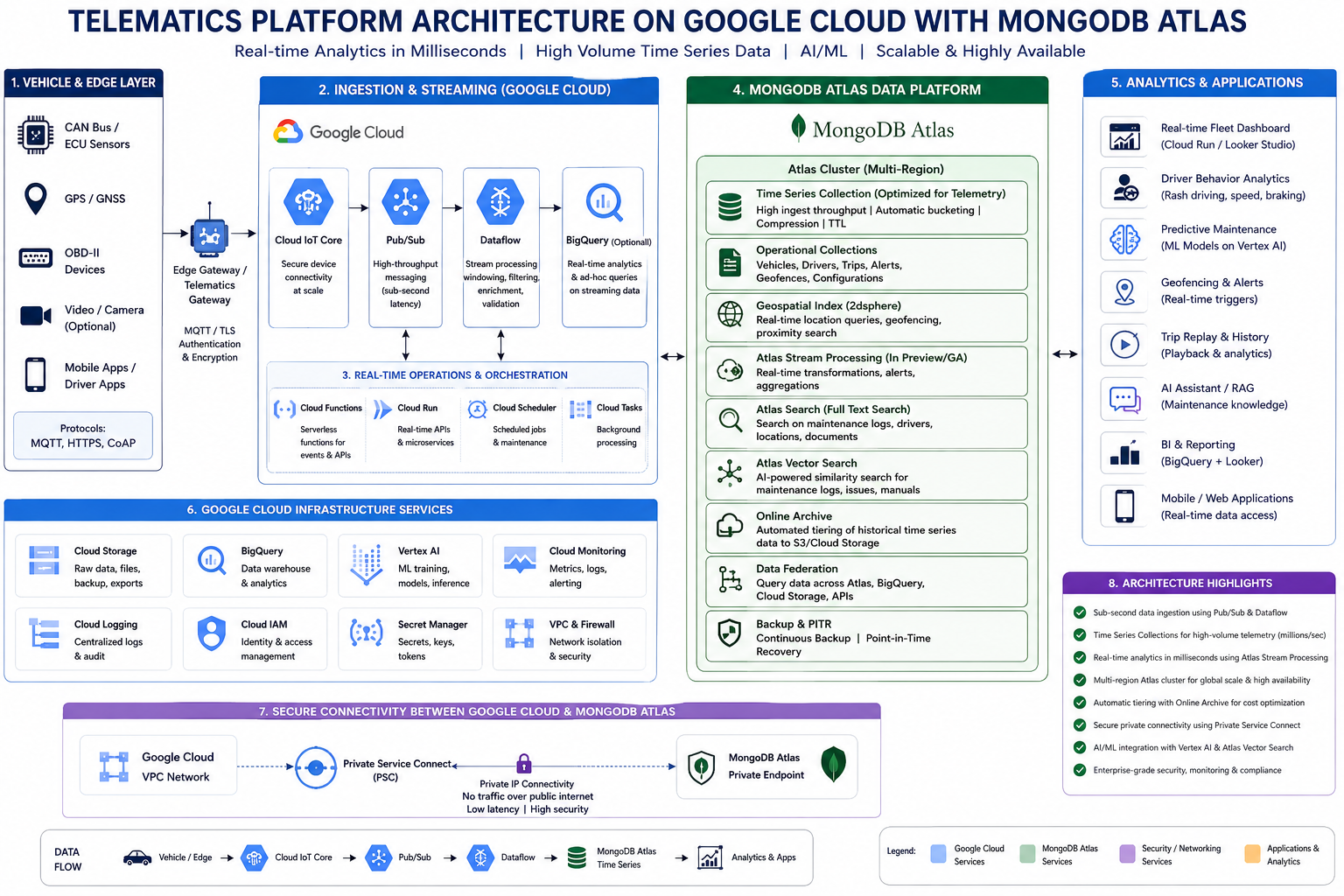
- Real Time Telematics Platform on MongoDB
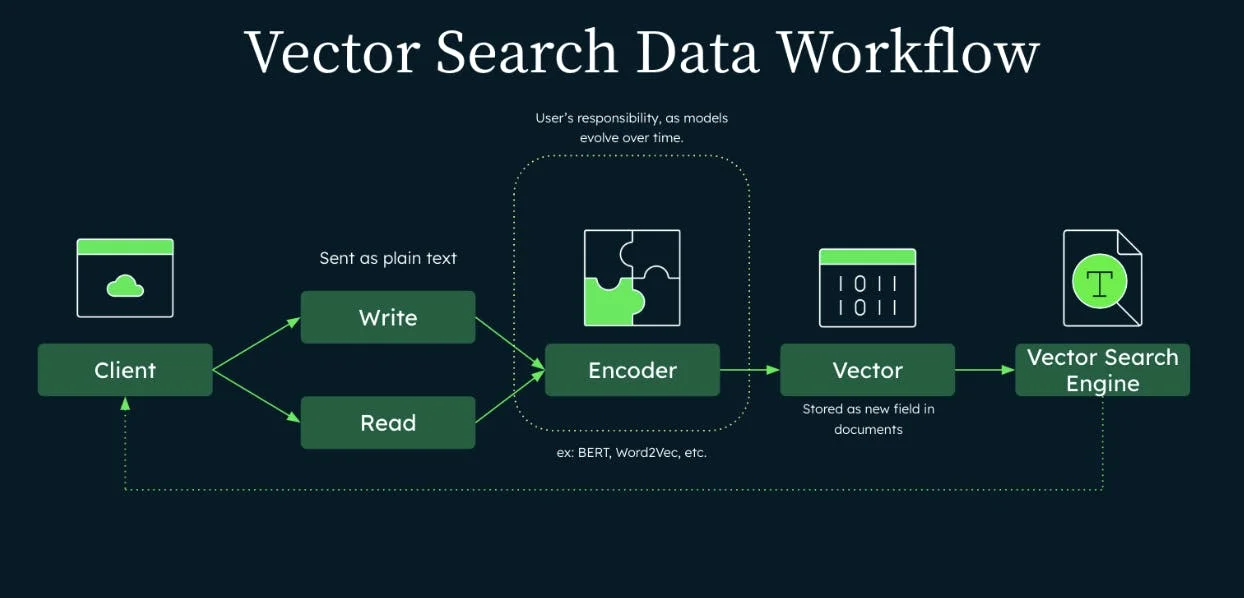
- MongoDB Zero Shot Semantic Serach
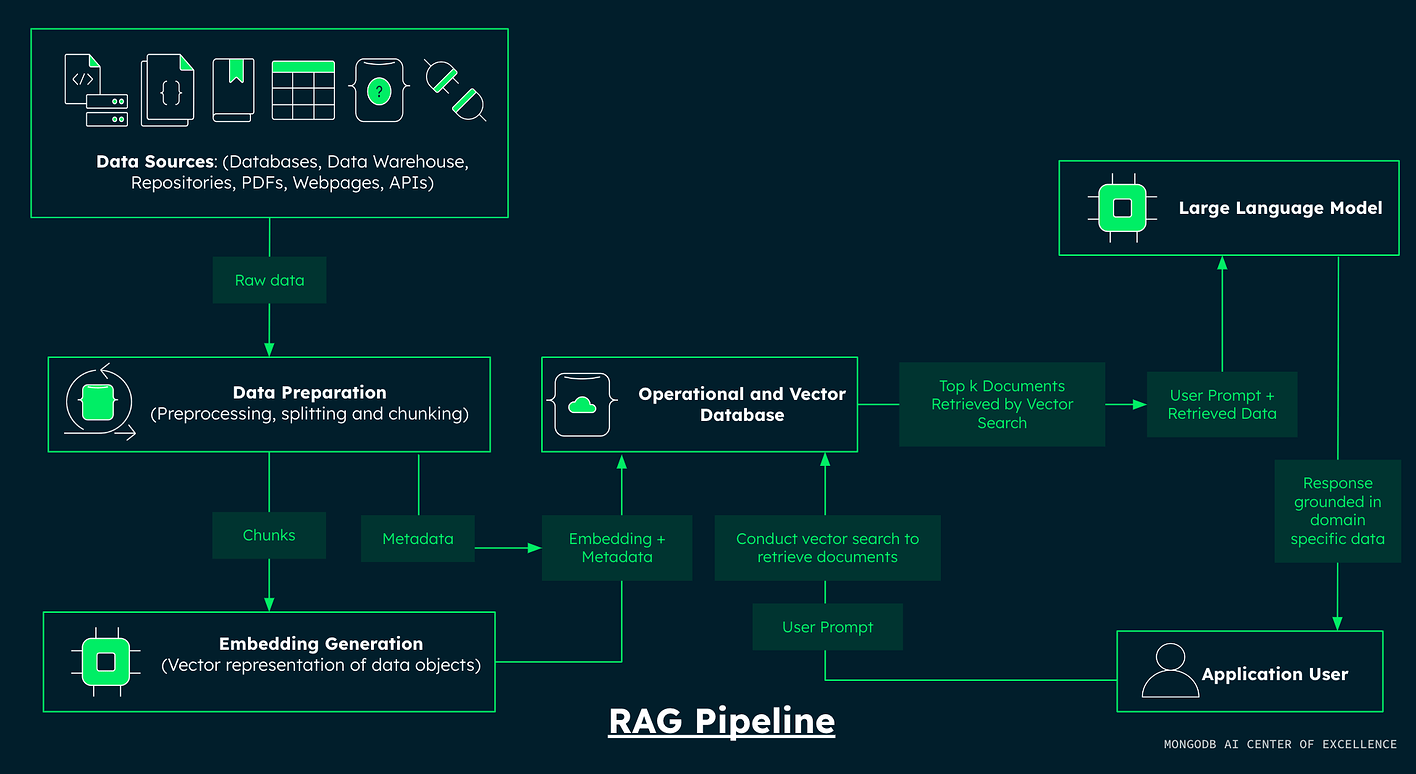
- Building an AI-Powered Recommendation System using RAG, MongoDB, Ollama, and Gemini
- AI Database Features
- Understanding Agentic AI: The Shift from Passive Models to Autonomous Agents
- The AI Blockchain
- Model Context Protocol (MCP) vs Agent to Agent (A2A) Protocol
- Responsible AI
- Building a CI/CD Pipeline for Machine Learning Using AWS Services
- DeepSeek Architecture
- Machine Learning for Beginners. Your roadmap to success.
- The Machine Learning Algorithms List: Types and Use Cases
- Harnessing Machine Learning for Advanced A/V Analysis and Detection
- TensorFlow Lite vs PyTorch Mobile for On-Device Machine Learning
- Generative AI presents new opportunities for accelerating human achievement
- Unlocking the true potential of AI with UiPath business automation
- AI for good: Three principles to use AI at work responsibly
- Transforming healthcare document processing with AI

Machine Learning for Beginners. Your roadmap to success.
Machine Learning for Beginners. Your roadmap to success.
by Priyansh Soni | Feb 26, 2024 | Machine Learning
Are you eager to dive into the world of machine learning but unsure where to start? This blog is your go-to manual, designed for beginners seeking to master machine learning skills.
The article will take you through a detailed roadmap with some of the best resources available on the internet. We include machine learning courses, articles, tutorials, and books, all from scratch, that’ll help you begin your journey into machine learning and data science.
This step-by-step guide will take you from the very basics of machine learning, diving deep into the algorithms, all the way to the best model-building techniques and more advanced topics like deep learning and artificial intelligence.
Every part has a dedicated resources section for beginners to explore various courses and articles available on the internet for related topics.
Buckle up for the journey!
Roadmap to Learning
- Introduction to Machine Learning
- Prerequisites for Machine Learning
- Machine Learning Fundamentals
- Machine Learning Algorithms
- Courses to Grasp Fundamentals
- Data Processing and Feature Engineering
- Model Building Techniques
- Model Evaluation Techniques
- IDEs and Online Platforms
- Advanced ML and Deep Learning
1. Introduction to Machine Learning
- Machine learning is a branch of computer science and a subset of artificial intelligence where we train a machine/computer to learn patterns from data and then make predictions based on those patterns.
- From recommending movies on Netflix to predicting the next word you’ll type, machine learning is behind many of the technologies we use every day. That includes industries like healthcare, finance, and transportation, among others.
- Learning machine learning is incredibly exciting and valuable. It opens up doors to endless possibilities, allowing you to solve real-world problems, automate tasks, and make better decisions based on data.
Check the links below to learn more about Machine Learning and Data Science:

2. Prerequisites for Machine Learning
Basics of Statistics
By understanding statistical concepts, you can make informed decisions about which machine learning algorithms to use, how to evaluate their performance, and how to interpret the results.
Some important statistical concepts for machine learning are:
- Descriptive Statistics:
-
- Mean, median, mode
- Variance and standard deviation
- Percentiles and quartiles
- Skewness and Kurtosis
- Probability:
- Probability distributions (e.g., Gaussian/Normal, Poisson, Binomial)
- Conditional probability
- Bayes‘ theorem
- Random variables and expected values
- Inferential Statistics:
- Hypothesis testing (e.g., t-tests, chi-squared tests)
- Confidence intervals
- Type I and Type II errors
- p-values
- Data Sampling
- Random sampling techniques
- Cross-validation (k-fold, leave-one-out)
- Bootstrap resampling
Basics of Programming
- In the realm of machine learning, programming skills are essential for bringing algorithms to life and manipulating and transforming data into insights. So you’ll have to wear the hat of a programmer diving further!
- Programming languages popular for Machine Learning and analytics are Python, R, Matlab, and Java.
- Python is the most commonly used programming language in machine learning due to its simplicity, versatility, and extensive libraries and data analytics tools like NumPy, Pandas, and Scikit-learn.
- Many machine learning frameworks like Scikit-learn, PyTorch, TensorFlow, and Keras, are built for Python which allows beginners to quickly prototype machine learning models and offers a rich ecosystem for data manipulation, visualization, and model building.
3.Types of Machine Learning
There are fundamentally 3 types of machine learning strategies:
- Supervised Learning:
- In supervised learning, the algorithm is trained on a labeled dataset, where each data point is associated with a corresponding target variable. The goal is to learn a mapping from input features to output labels based on the provided examples.
Supervised Learning can be further divided into Regression and Classification
- Unsupervised Learning:
In unsupervised learning, the algorithm is presented with an unlabeled dataset, and its task is to find patterns, structures, or relationships within the data without explicit guidance. This type of learning is used where algorithms autonomously identify hidden patterns and insights.
- Reinforcement Learning:
- Reinforcement learning is a type of machine learning where an agent learns to interact with an environment by performing actions and receiving rewards or penalties in return. The goal is to learn a policy that maximizes cumulative rewards over time, enabling the agent to make informed decisions and adapt its behavior based on feedback from the environment.
4. Machine Learning Algorithms
Machine learning algorithms serve as the cornerstone of predictive modeling and decision-making, empowering computers to autonomously learn from data and make predictions or decisions.
Supervised Learning
Regression
Regression algorithms facilitate the prediction of continuous values based on input features. Common regression algorithms include linear regression, polynomial regression, decision tree regression, etc
Regression Algorithms —
Linear Regression – Linear regression follows linear algebra and models the relationship between the dependent variable and one or more independent variables using a linear equation.
- Polynomial Regression – Polynomial regression extends linear regression by fitting a polynomial function to the data, allowing for more complex relationships between variables.
Decision Tree Regression – Decision tree regression models incorporate tree data structures to make decisions at every node.
Random Forest Regression – Random forest regression is an ensemble bagging technique that builds multiple decision trees (weak learners) and aggregates their predictions to improve accuracy and reduce overfitting.
Gradient Boosting Regression – Gradient boosting regression is an ensemble boosting technique that sequentially builds an ensemble of weak regression models, each focusing on the residuals of the previous model.
Support Vector Regression (SVR) – Support vector regression finds the hyperplane that best fits the data while minimizing deviations from the observed targets within a specified margin of tolerance.
Classification
Classification enables the prediction of discrete labels or categories from input data. They are integral to tasks such as email spam detection, sentiment analysis, and medical diagnosis. Widely used classification algorithms include logistic regression, decision tree classification, support vector machines (SVM), k-nearest neighbors (KNN), etc.
Classification Algorithms —
Logistic Regression – Logistic regression models the probability of a binary outcome based on one or more predictor variables using a logistic function.
Decision Tree Classification – Decision tree classification partitions the feature space into distinct regions and predicts the class label for each observation based on majority voting within each region.
Random Forest Classification – Random forest classification builds multiple decision trees and aggregates their predictions to improve accuracy and reduce overfitting in classification tasks.
Support Vector Machine (SVM) – Support vector machine constructs a hyperplane or set of hyperplanes in a high-dimensional space to separate data points into different classes, maximizing the margin between classes.
Naive Bayes Classification – Naive Bayes classification is a probabilistic algorithm based on Bayes‘ theorem and the assumption of independence between features.
K-Nearest Neighbors (KNN) Classification – K-nearest neighbors classification predicts the class label for a new data point by identifying the k nearest neighbors in the feature space and assigning the majority class label among them.
Gradient Boosting Classification – Gradient boosting classification sequentially builds an ensemble of weak classifiers, each focusing on the mistakes of the previous model, to improve predictive performance in classification tasks.
Unsupervised Learning
Clustering Algorithms
Clustering algorithms are pivotal for grouping similar data points into clusters based on their intrinsic similarities. They find applications in customer segmentation, image segmentation, and anomaly detection.
Key clustering algorithms are:
- K-means clustering – K-means partitions data into K clusters by iteratively assigning each point to the nearest centroid and updating centroids based on mean distance. It’s used widely for customer segmentation anomaly detection, etc.
Hierarchical clustering – Hierarchical clustering builds a cluster hierarchy by merging or splitting clusters based on similarity. It’s popularly used in social network analysis gene expression studies, etc.
DBSCAN – BSCAN identifies clusters based on density connectivity, grouping closely packed points. It’s used widely in spatial data analysis anomaly detection, etc.
Dimensionality Reduction
Dimensionality reduction algorithms streamline data by reducing the number of input features while retaining critical information. They are beneficial for tasks like data visualization, feature extraction, and noise reduction.
Key dimensionality reduction algorithms are:
Principal Component Analysis (PCA)
t-distributed stochastic neighbor embedding (t-SNE)
Linear Discriminant Analysis (LDA)
Reinforcement Learning Algorithms
Reinforcement Learning (RL) is about an agent learning to interact with an environment to maximize rewards.
Here are some major RL algorithms:
- Q-Learning: Q-Learning is a model-free reinforcement learning algorithm that learns the optimal action-selection policy for an agent interacting with an environment.
- Policy Gradient Methods: Policy gradient methods, such as Proximal Policy Optimization (PPO), are popular for directly learning policies to maximize rewards. They offer simplicity and efficiency in training policies for a wide range of tasks.
5. Courses to Grasp Fundamentals
This section caters to the machine learning courses available on the internet which cover everything from the basics of algorithms to practicing exciting machine learning projects and modeling with hands-on experience.
6. Data Preprocessing and Feature Engineering
- Data preprocessing involves cleaning, transforming, and preparing raw data for machine learning algorithms. This includes handling missing values, dealing with outliers, scaling or normalizing features, handling categorical data, data imputation, data splitting into training data and test data, handling imbalanced data, and creating synthetic data.
Feature engineering is the process of creating new features or transforming existing features to improve the performance of machine learning models. Techniques such as one-hot encoding, feature scaling, and dimensionality reduction are used to extract relevant information from the data and enhance model accuracy.
7. Model Building TechniquesModel-building techniques play a crucial role in building machine learning models, which are suitable to a given task based on factors like performance, interpretability, and computational efficiency.
Some model-building techniques are:
- Hyperparameter Tuning – This involves optimizing the hyperparameters of a machine learning model to improve its performance.
- Hyperparameter Tuning for Machine learning – Train in Data
- Hyperparameter Tuning in Python – neptune.ai
- Introduction to hyperparameter tuning – pyimagesearch
- Hyperparameter Tuning for Machine learning – Train in Data, online course
- Cross-Validation – This involves splitting the dataset into multiple subsets, training the model on different subsets, and evaluating its performance on the remaining subsets to ensure robustness and reliability.
- Cross Validation in machine learning – JavaTPoint
- Cross Validation in machine learning – GeeksForGeeks
- Ensemble Learning – Techniques such as bagging, boosting, and stacking, which combine multiple machine learning models to improve prediction accuracy and generalization performance.
- Introduction to Ensemble Learning Algorithms – MachineLearningMastery
- A Comprehensive Guide to Ensemble Learning – neptune.ai
- Regularization – Regularization techniques are used to prevent overfitting and improve the generalization performance of machine learning models. Techniques like L1 regularization (Lasso), L2 regularization (Ridge), and dropout regularization are commonly used to penalize complex models and encourage simplicity.
- Regularization – einfochips
- Regularization Part 1&2 – StatQuest
8. Model Evaluation
Model evaluation is a critical step in assessing the performance and effectiveness of machine learning models using performance metrics like:
Regularization Performance Metrics
- Mean Squared Error (MSE): The average squared difference between the predicted and actual values.
- Root Mean Squared Error (RMSE): The square root of the average squared difference between the predicted and actual values.
- R-Squared: The proportion of variance in the dependent variable that is explained by the independent variables, with values closer to 1 signifying a better fit.
Classification Performance Metrics
- Confusion Matrix: Summarizes a classification model’s performance by comparing actual and predicted values in a tabular format.
- Accuracy: Represents the proportion of correct predictions made by the model out of all predictions.
- Precision: Reflects the ratio of true positive predictions to all positive predictions made by the model, highlighting its ability to avoid false positives.
- Recall: Indicates the ratio of true positive predictions to all actual positive instances, demonstrating the model’s capability to identify positives correctly.
- F1 Score: Quantifies the balance between precision and recall, providing a single metric that combines both measures into a harmonic mean.
- Receiver Operating Characteristic (ROC) Curve: Illustrates the trade-off between true positive rate and false positive rate at various classification thresholds, by calculating the area under the ROC curve (AUC).
Resources:
- Performance Metrics in Machine Learning – neptune.ai
- Top Performance Metrics in Machine Learning – v7labs
9. IDEs and Online Platforms
Integrated Development Environments(IDEs) are essential tools for machine learning (ML) practitioners, providing a comprehensive platform for writing, testing, and deploying ML models. Many IDEs are open-source and provide APIs for interacting with machine learning libraries and frameworks like TensorFlow, PyTorch, Scikit-learn, etc.
10. Advanced ML and Deep Learning
Neural Networks are the building blocks of advanced ML and Deep Learning. They employ interconnected layers of nodes to learn complex patterns and relationships in the data, making it suitable for big data computation and complex tasks.
Neural Network models are state-of-the-art and have use cases in domains like Computer Vision, Natural Language Processing (NLP), Speech Recognition, Image Recognition, Autonomous Vehicles and Self-Driving cars, Robotics, and the popular Generative AI.














Subscribe to our mailing list to get the new updates!

Subscribe our newsletter to stay updated